Extract Reference
January 2015
support@pureload.com
Extract Reference |
|
| PureTest
5.2 January 2015 |
http://www.pureload.com support@pureload.com |
The basic extract tasks supports various techniques to extract data
from a response (generated by any task) and assign the extracted data
to a variable. This document describes more about the various
techniques
used.
The tasks ExtractTask and HttpExtractTask optionally
supports using regular expressions to extract data. Using the
tasks you specify a start and an end pattern and all data
between these patterns are extracted.
In this section we will give references to more information about
the regular expression language used ans well as a few examples.
Regular expressions are a way to describe a set of strings based on
common characteristics shared by each string in the set. The version of
Regular Expressions used by the extract tasks is the standard as
supported by Java, which is most similar to that found in Perl.
For details on the regular-expression constructs, see the Java
Pattern
class documentation. In addition, the Java
Tutorial on Regular Expressions might be useful.
Let's say that we have an HTML content as follows:
| <html> <body> <!-- ... --> <a title="OK" href="/Controller?action=view&cat=4">Have Fun</a> <a title="OK" href="/Controller?action=view&cat=5">Get It All</a> <!-- ... --> </body> </html> |
Now we want to extract the "href" that corresponds to the "Get It
All" string. To handle this we specify the following parameters to the
ExtractTask:
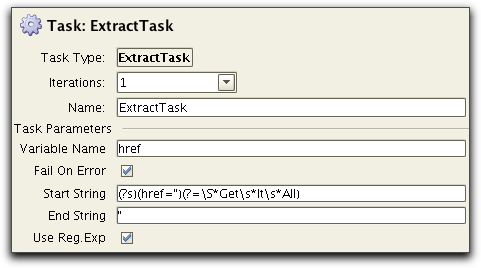
The somewhat tricky part here is the Start regular expression:
The End pattern is often easy as in this example, simply a double
quote (").
There is also a specialized RegexTask which stores capturing groups
in variables. This allows for more straightforward regular
expressions. The above example can be expressed as:
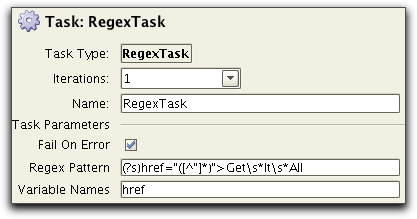
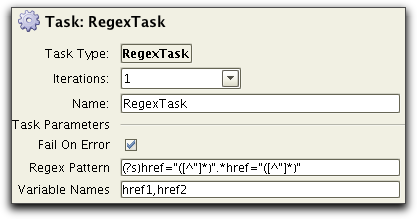
It is also possible to use more than one variable by entering a comma
separated list of variable names. The number of variables must match
the number of capturing groups. For example, to store both href values
in the above HTML example as variable href1 and href2:
Using regular expression is powerful, but also sometimes quite complicated. An option is in many cases using XPath and HtmlXpathExtractTask (see the example below).
The tasks XmlXPathExtractTask and HtmlXpathExtractTask
uses XML Path Language (XPath) expressions to define what data to be
extracted. The difference between the two tasks is that
XmlXPathExtractTask can only be used with well-formed XML and
(optionally) namespaces. HtmlXpathExtractTask on the other hand uses a
"relaxed" XML parser to allow
extract using XPath even if XML/XHTML/HTML content isn't well formed.
I.e. a typical HTML/XHTML page.
In this section we will give references to more information about
XPath as well as a few examples.
XPath uses path expressions to select nodes or node-sets in an XML
document. For more information about XPath and XPath expressions we
recommend any XPath tutorials, for example: http://www.w3schools.com/XPath/.
For a simple example, let say that we have a response as follows:
| <?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore> |
From this response we want to extract data. A few examples:
| We want to extract | XPath Expression | Result |
| title of the first book |
/bookstore/book[1]/title | Everyday Italian |
| price of the last book | /bookstore/book[last()]/price |
39.95 |
| title of 1'st book with price
greater than 35 |
/bookstore/book[price>35][1]/title |
XQuery Kick Start |
| 1'st author of the 1'st book in
the WEB category |
/bookstore/book[@category='WEB'][1]/author[1] |
James McGovern |
When XPath is used to extract data from an Web Service response (such as SOAP) it's common that XML Namespaces are used. When namespaces are used it's important that you understand the basics regarding namespaces.
The following is a simple SOAP XML response, using namespaces:
| <?xml version="1.0"?> <SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"> <SOAP-ENV:Body> <m:ThumbnailResponse xmlns:m="http://ast.amazonaws.com/doc/2006-05-15/"> <aws:Response xmlns:aws="http://ast.amazonaws.com/doc/2006-05-15/"> <aws:OperationRequest> <aws:RequestId>3f8ceabd-2d15-47f0-b35e-d52ee868a4a6</aws:RequestId> </aws:OperationRequest> <aws:ThumbnailResult> <aws:Thumbnail Exists="true">http://location_to_thumbnail_for_www.alexa.com</aws:Thumbnail> <aws:RequestUrl>www.alexa.com</aws:RequestUrl> </aws:ThumbnailResult> <m:ResponseStatus> <m:StatusCode>Success</m:StatusCode> </m:ResponseStatus> </aws:Response> <aws:Response xmlns:aws="http://ast.amazonaws.com/doc/2006-05-15/"> <aws:OperationRequest> <aws:RequestId>3f8ceabd-2d15-47f0-b35e-d52ee868a4a6</aws:RequestId> </aws:OperationRequest> <aws:ThumbnailResult> <aws:Thumbnail Exists="true">http://location_to_thumbnail_for_www.amazon.com</aws:Thumbnail> <aws:RequestUrl>www.amazon.com</aws:RequestUrl> </aws:ThumbnailResult> <m:ResponseStatus> <m:StatusCode>Success</m:StatusCode> </m:ResponseStatus> </aws:Response> </m:ThumbnailResponse> </SOAP-ENV:Body> </SOAP-ENV:Envelope> |
From this response we want to extract data. To do this we first have
to define namespace prefix mapping (a parameter to the
XmlXPathExtractTask). Let's use the following mapping:
| SOAP-ENV | http://schemas.xmlsoap.org/soap/envelope/ |
| m |
http://ast.amazonaws.com/doc/2006-05-15/ |
| aws |
http://ast.amazonaws.com/doc/2006-05-15/ |
Now we can extract data as in the following examples:
The HtmlXpathExtractTask is based on XPath, but uses a relaxed XML
parser, meaning that it is suitable for HTML/XHTML content.
As an example, let's say that we have the same content as in
previous example, where we uses regular expressions:
| <html> <body> <!-- ... --> <a title="OK" href="/Controller?action=view&cat=4">Have Fun</a> <a title="OK" href="/Controller?action=view&cat=5">Get It All</a> <!-- ... --> </body> </html> |
Now we want to extract the "href" that correspons to the "Have Fun"
string. To handle this we specify the following parameters to
the HtmlXpathExtractTask:
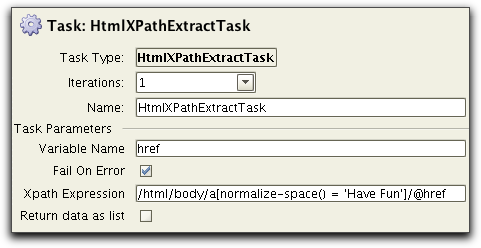
The only thing that complicates the XPath expression is that we need
to handle that the "Have Fun" string we are looking for contains
whitespace (including a line break). The solution is to use the XPath
function normalize-space().