Best Practices
January 2015
support@pureload.com
Best Practices |
|
| PureLoad
5.2 January 2015 |
http://www.pureload.com support@pureload.com |
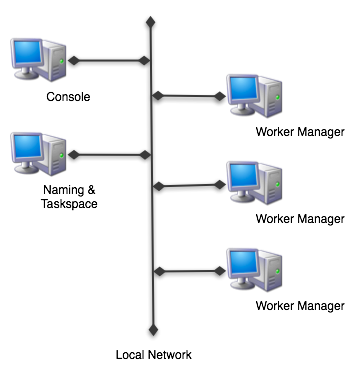
The PureLoad runtime can be configured in many ways. A common and
recommended configuration for larger load tests are as follows:
The number of worker threads which you can effectively use per
worker
depends
on the capacity of your hardware and which OS you use. In general,
modern server
OS:es
(for example Linux and Windows Server editions) have better
threading
capabilities compared to a desktop OS (such as Windows XP).
But in addition it also depends on:
So, to find out how many worker threads you can run in your
environment, the best is to start out with a low number of threads
and monitor the
workers during execution. From this point of view you should check
the
CPU usage and make sure it stays below 90% most of the time.
It is important to understand that using a load test tool you are
always
simulating load. It is not real users doing real work accessing
your
servers under test. So what is a realistic test? This depends on
several
factors, but our suggestion in general is that you should look at
the
goals and requirements you have on your system.
Depending on the system under test, it might be a useful
simulation
to focus on requests per second, instead of trying to simulate
real
clients. In other cases you really have to simulate real clients
as
close
as possible. The following gives some hints on what you should
consider
in these cases.
If you want to simulate "real" users, the scenarios executed by
each
worker thread must simulate how a real user would access the
server
application. This means using realistic data (see below) and
include
"wait (or think) times" in the scenario, using SleepTask and
RandomSleepTask. When you have a scenario like this, one worker
thread
will correspond to one simulated virtual client.
You probably also want to use several scenarios simulating
different
users doing different things.
Using realistic data is essential in trying to simulate real clients. It is not enough to use a recorded (using the HTTP recorder) scenario. Repeating the same requests, with the same values will most likely produce unrealistic response values.
Instead you have to use dynamically generated values, using parameter
generators, generating data for different user accounts etc.
A user connecting at 100Mbps through a local network and a user
connecting with DSL connection might not have the same impact on
the
server. In PureLoad, the simulated bandwidth may be limited by
using
the
HttpInitTask.
When testing a web application, using different IP addresses is
normally not required. But for example if load balancers is used,
they
might use the client IP address to balance the load over several
servers. In this case you have to make sure you simulate access
from
different IP addresses.
If many IP addresses are required, it is possible to configure
several virtual IP addresses on the worker hosts. The HTTP tasks
(and most of the network related tasks) in PureLoad supports
defining which IP address to use. This means that you can simulate
different IP address using the same worker host. For massive
amount of IP addresses, there is a custom Linux kernel module
available which uses Source Network Address Translation (SNAT) to
change the source IP address on-the-fly. This SNAT kernel module
is currently only available for Linux.
Read more about virtual IP addresses, IP Pool tasks and SNAT in the Virtual IP Address Reference and the Linux SNAT Kernel Module documents.
When running a load test in PureLoad over a long time (say a
weekend) you should be aware of:
With this in mind, we suggest that you check the following in the
Console Tool
Properties
before you start the execution:
Massive testing, using many thousands of simulated clients, where
the scenario initiates and keeps a session alive (for example an
HTTP
session, using cookies), the default model where each worker
thread
corresponds to one native thread sets a limit. Read more about Worker Threads above.
For certain scenarios where the main focus is to test a massive
amount of sessions performing infrequent operations, the thread
limitation can be avoided by using the Worker Threading mode
Multi.
Running in this mode, the worker will execute multiple worker
threads
for each native thread.
Consider the following scenario showing a simple use-case of some web based application:
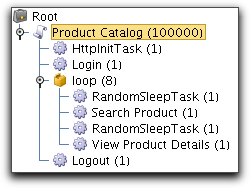
Let us say that we want to simulate how 100,000 users use the
application during the course of a day. The average user logs in
in the
morning between 8:00 AM and 9:00 AM and then makes a search every
other
hour and finally logs out at the end of the day. The sleep task
prior
to searching is set to sleep randomly for zero to two hours. The
second
sleep task simulates think time and is set to 5 - 10
seconds.
This means that the server will receive 100,000 login requests
randomly
distributed over one hour - about 30 logins per second. The rest
of the
day it will receive about 30 searches per second and 30 view
product
requests per second. In this example, the server can easily handle
these requests and the response times are near zero.
Using native threads would require somewhere around 30 to 100
machines to execute this scenario. Since the amount of actual
requests
per second is never more than about 60 per second, it should be
enough
with a single worker machine if it could handle the amount of
threads.
This is where the Worker
Threading
mode Multi comes in. We set up a
worker with 100,000 threads configured to use Threading Multi with
a
ratio of 1000 and a delay of 3600:
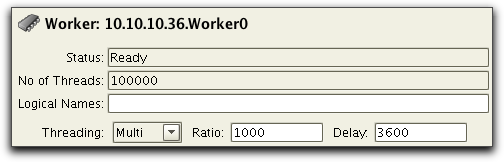
This means that the worker will use 100 native threads. The delay
is
set to 3600 to match that the users log in during one hour. Each
worker
thread will start with going to sleep for 0 to 3600 seconds. This
gives
the 100 native threads enough time to execute the 30 logins per
second.
It is important that the search/view loop contains a substantial
amount
of sleep task(s) (one hour in average in this case) to allow the
Threading Multi mode enough time to schedule the worker threads
properly.
Using Threading Multi requires careful thought. Resources are
easily
exhausted when the numbers are hundreds of thousands. The worker
will
log a warning message if it detects that it fails to execute the
tasks
in the correct rate:
| 14:17:41 [WARN] 10.10.10.36.Worker0.Thread0 Product
Catalog/Search Product execution lag: 12362 [ms] |
In the above example, the server response times were low. Had the
Search Product request instead had a response time of 0.5 seconds,
it
would be difficult to generate 60 requests per second with 100
native
threads and it would be necessary to increase the number of
machines
somewhat, but still no way near the 30 - 100 machines required
using
native threads.
PureLoad uses RMI (Java Remote Method Invocation) for internal
communication between servers and the
console and by default there is no control over the ports being
used by
RMI, which makes it hard to open up communication when firewalls
are
used.
There are however System
Properties to control all ports being used, and hence allow
communication through firewalls.
As an example, let us say that we have a network where the
Console
is
being used from another network than the servers and the networks
are
separated by a firewall:
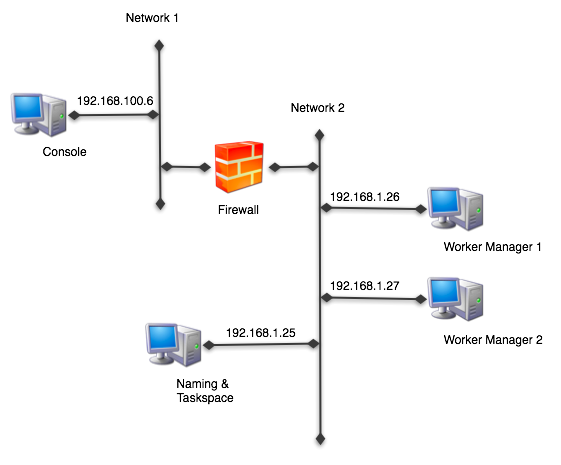
In this case we need to open up the firewall to allow
communication
from the console to the servers. We do this by first defining the
system properties for each server:
| naming.port=1099 naming.service.port=60002 taskspace.port=60003 taskspace.service.port=60004 |
| manager.port=60005 manager.service.port=60008 |
| manager.port=60007 manager.service.port=60008 |
The actual ports used can be any ports, with the exception of the naming.port that must match the PureLoad license.
Now you can open the ports 1099 and 60002-60008 in the firewall and communication will work as expected.
If NAT (Network Address Translation) is used, you also have to make sure the servers expose their remote IP address (i.e the address used outside the firewall) used to contact the servers. Use the external.host property for this.
If we in the example above must use IP address 192.168.100.126 to
reach Worker Manager 1, we simply specify:
| external.host=192.168.100.126 |
in the pureload.properties file for the manager.